上篇文章我们讲解了elasticsearch的安装,这次我们来搞一下,如何在自己的项目中集成elasticsearch。 正常来讲spring-data中都会提供相应的starter,让我们方便的使用各种Template操作对应的组件,比如常用RedisTemplate, JdbcTemplate等,其实spring-data中也提供的相应的elasticsearch的对应工具。但是我这里并没有使用,而是直接使用的elasticsearch原生api实现的。为什么这么做呢,因为spring-data-elasticsearch 最新的版本3.2,最高支持的elasticsearch版本为6.8, 而我们用的是7.2的版本,并且官方建议我们使用的jar版本最好和软件版本一致。

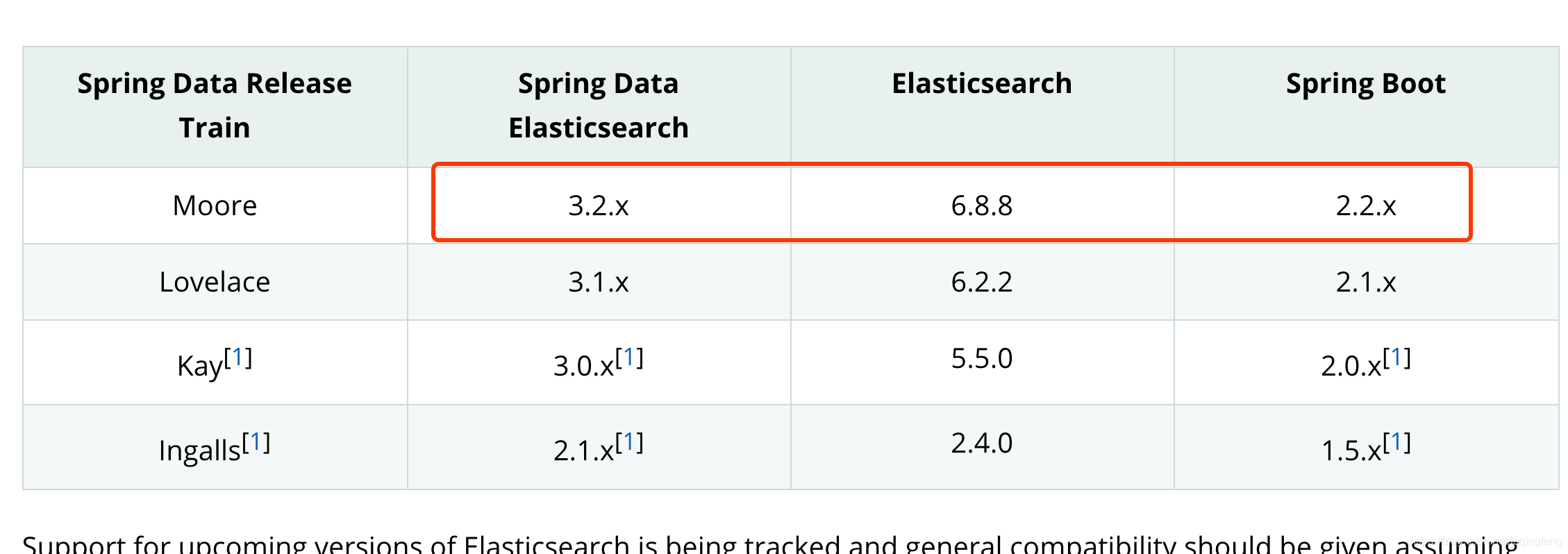
还有一个问题, 是关于客户端的, spring-data-elasticsearch中默认使用的是TransportClient, 这个客户端在7这个版本中已经不再建议使用了,并且将会在8的版本中彻底移除。而我们用的是7这个版本,目前推荐使用的elasticsearch的高级客户端,HighLevelRestClient. spring-data-es中声明会一直支持TransportClient,只要你的这个es版本支持。当然,spring-data-es中也是支持高级别客户端的,但是还有由于支持版本过低的问题,所以我最后还是决定采用原生客户端。如果大家用的es版本比较低,还是可以使用spring-data-es的。


接下来我们来集成项目,集成之前,大家需要了解一下es中的一些专有名词,比如什么是索引,类型,文档,同时你要了解es是干什么用的。es最主要的功能就是查询,也就是他查东西的速度非常快,并且支持分词,全文检索。如果我们在mysql中查询一遍文章的内容,其实是非常痛苦的,我们可能必须得使用 like 或者拼接or去查询多个字段,并且有些场景是无法实现的,比如你的文章中的内容中包含 ”一朵鲜花“, 而你去搜索 ”一朵花“ 这种情况你是查不到的,但是es可以,因为es可以分词, 他会一朵鲜花, 分成 ”一朵“ ”鲜花“ 两个词,再把 ”一朵花“ 分成 ”一朵“ 和 ”花“ (注: 这里是个人方便理解,可能具体分词不是这么分的,大家领悟精髓)。 就很容易做到查询。 同时es查询的比较快,也是因为他的内部采用了倒叙索引,关于倒叙索引的原理,大家可以去找找资料,这里就不展开说了。
一。 引入jar包
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.2.0</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-client</artifactId> <version>7.2.0</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>7.2.0</version> </dependency>二。封装工具类,这里主要使用高级别客户端封装, 主要封装了创建索引,判断索引是否存在,删除索引, 插入文档的功能,还有一些高级功能还没有 研究完,比如高亮和分页,我会一边研究一边更新,先给出一些简单的操作demo.后续文章我们在深入展开。
@Component @Slf4j public class EsUtil { @Resource private RestHighLevelClient restHighLevelClient; /** * 创建索引(默认分片数为5和副本数为1) * @param indexName * @throws IOException */ public boolean createIndex(String indexName) throws IOException { CreateIndexRequest request = new CreateIndexRequest(indexName); request.settings(Settings.builder() // 设置分片数为3, 副本为2 .put("index.number_of_shards", 3) .put("index.number_of_replicas", 2) ); request.mapping(generateBuilder()); CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT); // 指示是否所有节点都已确认请求 boolean acknowledged = response.isAcknowledged(); // 指示是否在超时之前为索引中的每个分片启动了必需的分片副本数 boolean shardsAcknowledged = response.isShardsAcknowledged(); if (acknowledged || shardsAcknowledged) { log.info("创建索引成功!索引名称为{}", indexName); return true; } return false; } /** * 判断索引是否存在 * @param indexName * @return */ public boolean isIndexExists(String indexName){ boolean exists = false; try { GetIndexRequest getIndexRequest = new GetIndexRequest(indexName); getIndexRequest.humanReadable(true); exists = restHighLevelClient.indices().exists(getIndexRequest,RequestOptions.DEFAULT); } catch (IOException e) { e.printStackTrace(); } return exists; } /** * 删除索引 * @param indexName * @return */ public boolean delIndex(String indexName){ boolean acknowledged = false; try { DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(indexName); deleteIndexRequest.indicesOptions(IndicesOptions.LENIENT_EXPAND_OPEN); AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT); acknowledged = delete.isAcknowledged(); } catch (IOException e) { e.printStackTrace(); } return acknowledged; } /** * 更新索引(默认分片数为5和副本数为1): * 只能给索引上添加一些不存在的字段 * 已经存在的映射不能改 * * @param clazz 根据实体自动映射es索引 * @throws IOException */ public boolean updateIndex(Class clazz) throws Exception { Document declaredAnnotation = (Document )clazz.getDeclaredAnnotation(Document.class); if(declaredAnnotation == null){ throw new Exception(String.format("class name: %s can not find Annotation [Document], please check", clazz.getName())); } String indexName = declaredAnnotation.index(); PutMappingRequest request = new PutMappingRequest(indexName); request.source(generateBuilder(clazz)); AcknowledgedResponse response = restHighLevelClient.indices().putMapping(request, RequestOptions.DEFAULT); // 指示是否所有节点都已确认请求 boolean acknowledged = response.isAcknowledged(); if (acknowledged ) { log.info("更新索引索引成功!索引名称为{}", indexName); return true; } return false; } /** * 添加单条数据 * 提供多种方式: * 1. json * 2. map * Map<String, Object> jsonMap = new HashMap<>(); * jsonMap.put("user", "kimchy"); * jsonMap.put("postDate", new Date()); * jsonMap.put("message", "trying out Elasticsearch"); * IndexRequest indexRequest = new IndexRequest("posts") * .id("1").source(jsonMap); * 3. builder * XContentBuilder builder = XContentFactory.jsonBuilder(); * builder.startObject(); * { * builder.field("user", "kimchy"); * builder.timeField("postDate", new Date()); * builder.field("message", "trying out Elasticsearch"); * } * builder.endObject(); * IndexRequest indexRequest = new IndexRequest("posts") * .id("1").source(builder); * 4. source: * IndexRequest indexRequest = new IndexRequest("posts") * .id("1") * .source("user", "kimchy", * "postDate", new Date(), * "message", "trying out Elasticsearch"); * * 报错: Validation Failed: 1: type is missing; * 加入两个jar包解决 * * @return */ public IndexResponse add(String indexName, Object o) throws IOException { IndexRequest request = new IndexRequest(indexName); String userJson = JSON.toJSONString(o); request.source(userJson, XContentType.JSON); IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT); return indexResponse; } private XContentBuilder generateBuilder() throws IOException { XContentBuilder builder = XContentFactory.jsonBuilder(); builder.startObject(); { builder.startObject("properties"); { // es7及以后去掉了映射类型--person builder.startObject("name"); { builder.field("type", "text"); builder.field("analyzer", "ik_smart"); } builder.endObject(); } { builder.startObject("age"); { builder.field("type", "integer"); } builder.endObject(); } { builder.startObject("desc"); { builder.field("type", "text"); builder.field("analyzer", "ik_smart"); } builder.endObject(); } { builder.startObject("id"); { builder.field("type", "integer"); } builder.endObject(); } builder.endObject(); } builder.endObject(); /*.startObject().field("properties") .startObject().field("person") .startObject("name") .field("type" , "text") .field("analyzer", "ik_smart") .endObject() .startObject("age") .field("type" , "int") .endObject() .startObject("desc") .field("type", "text") .field("analyzer", "ik_smart") .endObject() .endObject() .endObject();*/ return builder; } }上面工具类中给出的索引结构是一个用户,只有id, name , age, desc 四个简单字段的结构
同时desc字段和姓名字段都是使用的ik-smart做的分词。
接下来大家就可以使用controller或者junittest来进行调用, 配合head插件观察数据。 整体的大致流程就是, index定义索引结构,然后我们把按格式数据存到es中, 使用es提供的高效api来做查询。 这篇文章先到这里,其实这里有一个痛点就是如果我们的数据结构比较复杂, 那么我们在创建索引的时候可能需要写出大量的代码,四个字段就这么多

所以这里其实我们可以根据实体的结构自动设计索引结构,像spring-data-es中就是根据我们在实体类上的注解,自动创建索引的。我这里也实现了自定义注解来创建es索引结构的方法,下一篇文章给大家介绍一下。
热门文章
- 青岛动物医学大学有哪些(青岛动物医院排名)
- vue实现页面刷新动画_vue.js_
- 中国动物疫苗市场分析报告最新(全国动物用疫苗销量排行)
- 瑞鹏宠物医院咋样(瑞鹏宠物医院咋样收费)
- 3月17日 - 最高速度21.2M/S,2025年Clash Nyanpasu每天更新免费节点订阅地址
- 2月12日 - 最高速度21.4M/S,2025年Clash Nyanpasu每天更新免费节点订阅地址
- 3月3日 - 最高速度20.3M/S,2025年Clash Nyanpasu每天更新免费节点订阅地址
- springboot集成elasticsearch7.2
- chrome浏览器隐藏滚动条
- numpy 中判断某字符串 array 是否含有子字符串